

Stufi di trovare la stessa canzone o la stessa immagine in tutte le directory del sistema? FSlint e FDUPES risolvono il problema.
FSlint è un GUI-tool che vi permette di rimuovere i file duplicati dal vostro sistema. FDUPES svolge i medesimi compiti di FSlint ma opera da terminale. Se avete la brutta abitudine di scaricare tutto dal web in modo selvaggio vi capiterà di trovare i medesimi file in più cartelle. Trovare e rimuovere tutti i duplicati è un vero supplizio oltre che una perdita di tempo, per questo vi consiglio di provare FSlint e FDUPES.
FSlint e FDUPES: trovare e rimuovere i file duplicati
Fslint ha una serie di ottime funzioni che vi aiutano in questo compito. Per installarlo aprite il terminale e date:
sudo apt install fslint
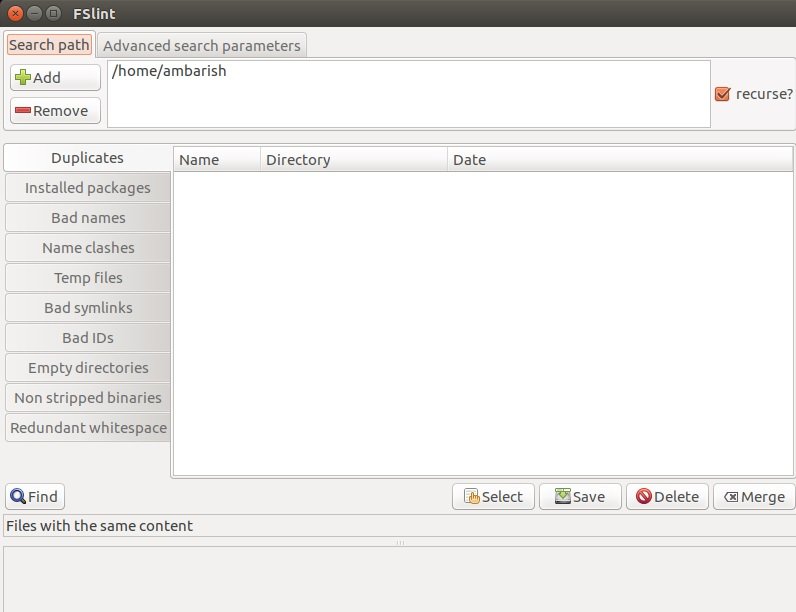
Come si evince dall’immagine qui sopra potete cercare i file duplicati, i pacchetti installati ma anche i file temporanei, le directory vuote e molto altro ancora. Vi basta selezionare il percorso e la funzione che vi interessa dal pannello sulla sinistra. Una volta terminata la ricerca potete selezionare i file da rimuovere.
Se volete fare le cose per bene potete accedere alla sezione “impostazioni avanzate” e settare i filtri di ricerca che fanno al caso vostro.
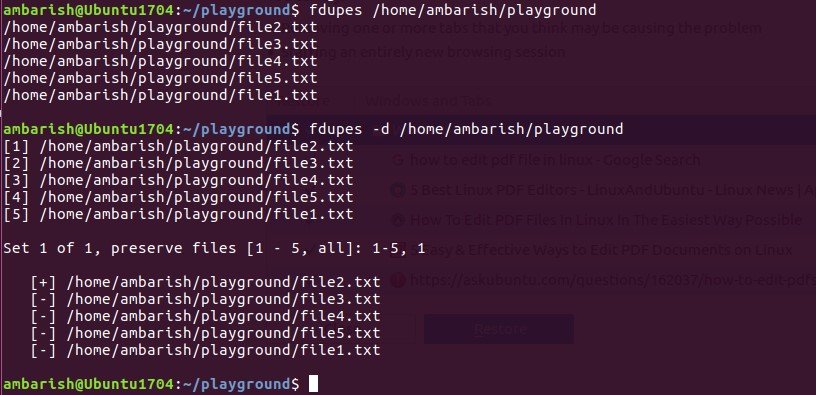
FDUPES, a differenza di Fslint, è una command-line utility. Vi trova i file duplicati in una determinata directory e vi permette di cancellarli.
Per installarlo date:
sudo apt install fdupes
Terminata l’installazione cercate i duplicati dando:
fdupes /path/to/folder
Per la ricerca ricorsiva usate l’opzione -r
fdupes -r /home
Potete cancellare manualmente i duplicati usando l’opzione -d:
fdupes -d /path/to/folder
Questo comando non cancella niente in modo automatico ma vi mostra i duplicati e vi permette di cancellarli uno ad uno. Se invece preferite la cancellazione automatica aggiungete l’opzione -N.
Per ulteriori dettagli vi rimanndo al sito ufficiale di FSlint e alla pagina GitHub di FDUPES.

Vi ricordiamo che seguirci è molto semplice: tramite la pagina Facebook ufficiale, tramite il nostro canale notizie Telegram e la nostra pagina Google Plus. Da oggi, poi, è possibile seguire il nostro canale ufficiale Telegram dedicato ad Offerte e Promo!
Qui potrete trovare le varie notizie da noi riportate sul blog. È possibile, inoltre, commentare, condividere e creare spunti di discussione inerenti l’argomento.
