
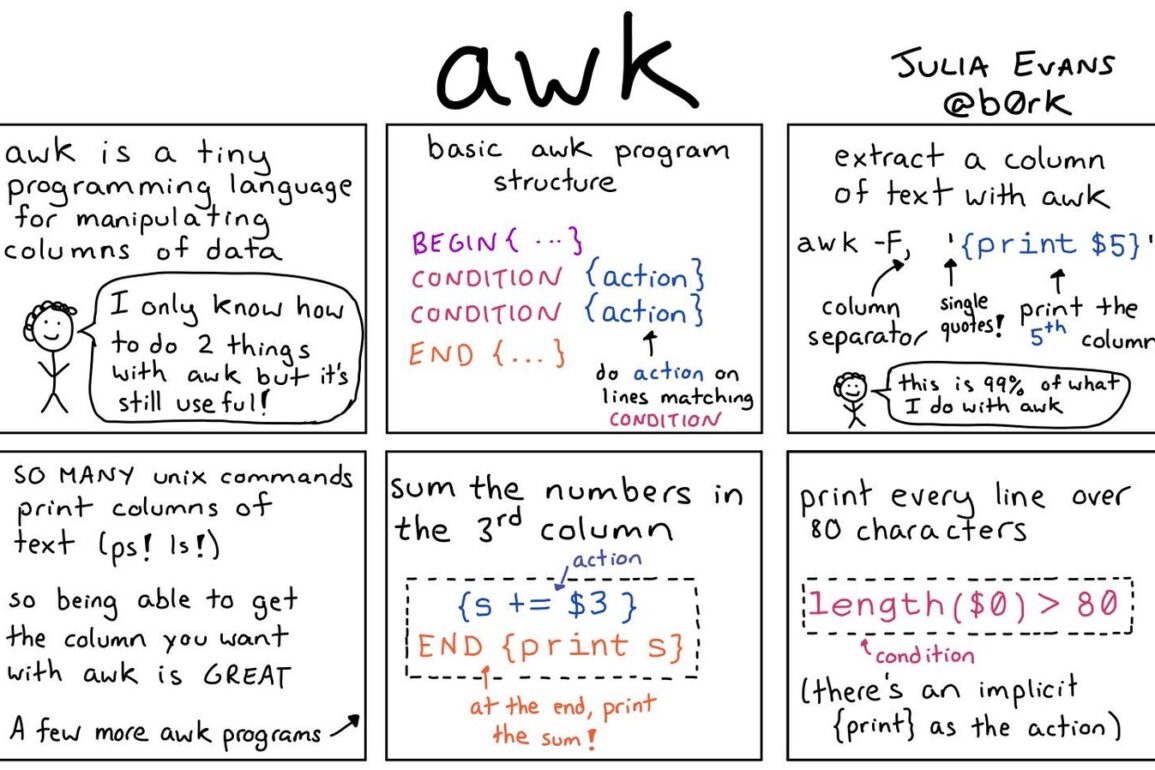
In questa mini guida voglio fare una breve introduzione al linguaggio Gawk. Questo strumento è davvero utile per manipolare i file, soprattutto se contenenti dati strutturati in tabelle. In conclusione, vi mostrerò anche come realizzare un piccolo report completo, che consenta di esporre i propri dati in maniera sintetica.
Gawk, tutto in una linea di codice
Gawk è l’implementazione nell’ambito del Progetto GNU del linguaggio di programmazione AWK, sviluppato originariamente per i sistemi UNIX verso la fine degli anni 70. AWK, a sua volta, è un linguaggio di scripting finalizzato alla manipolazione di dati di tipo testuale, sia in forma di file, che di flusso di dati, provenienti dallo standard input. Utilizzando il linguaggio Awk, quindi, si possono effettuare, con una singola riga di codice, una serie di operazioni complesse come l’estrazione e manipolazione dei dati, la creazione di report o l’esecuzione di calcoli. Per ottenere gli stessi risultati utilizzando linguaggi di programmazione tradizionali, sarebbe necessario creare un programma molto più complesso.
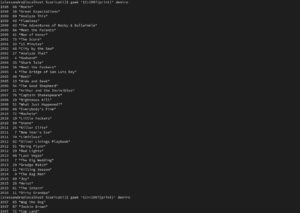 Esempi di filtri.
Esempi di filtri.Awk è un linguaggio di scansione ed elaborazione dei pattern. Per impostazione predefinita, legge lo standard input, lo processa linea per linea, e scrive lo standard output. La sintassi, quindi, sarà:
gawk [ opzioni in stile POSIX o GNU ] -f file di programma [ -- ] file gawk [ opzioni in stile POSIX o GNU ] [ -- ] testo del programma file
In particolare, per quanto riguarda il file di programma da utilizzare in Gawk, questo deve essere strutturato come il seguente schema:
@include "nome_del_file"
@load "nome_del_file"
criterio di ricerca { istruzioni }
function nome(lista di parametri) { istruzioni }
Come fare, dunque, per processare un file con Awk? Provate ad utilizzare questo come file d’esempio, è un semplice elenco dei film di De Niro dal 1968 al 2016, il relativo punteggio di Rotten Tomato ed il titolo del film. Il programma divide automaticamente ogni record in campi, numerando ciascuna colonna come $1, $2, $3 e così via. Di default, per separare ogni campo utilizza lo spazio, che corrisponde alla situazione del file di esempio. Per fortuna è possibile anche fornire un altro parametro, utilizzando l’opzione -F seguita dal separatore desiderato. Se vogliamo, ad esempio, stampare solo l’anno ed il voto del film, l’istruzione sarà:
awk '{print $1, $2}' deniro
Molto più interessante è la possibilità di filtrare il contenuto del file, per trovare la corrispondenza con un particolare pattern. Si intuisce la potenzialità di queste direttive dai seguenti esempi:
gawk '$1==1997{print}' deniro #stampa tutti i film del 1997
gawk '$1>1997{print}' deniro #stampa tutti i film dal 1998 in poi
Come creare un piccolo report
Vediamo adesso come creare un piccolo report in Gawk. Dato il file di esempio, andrò a filtrarne in contenuto e ad aggiungere una intestazione e dei dati di sintesi conclusivi. Non è richiesta alcuna particolare conoscenza di programmazione, è tutto molto intuitivo. Nella creazione delle view, è di solito opportuno inserire degli header alle colonne, per permettere una migliore fruizione dei contenuti. Si può effettuare questa operazione in combinazione con le altre appena viste, grazie ad un criterio di Awk, chiamato BEGIN. Questo, infatti, permette di eseguire un’istruzione prima dell’inizio del processo vero e proprio dei record. Un esempio renderà il tutto più chiaro:
#Aggiungiamo i titoli Anno, Voto e Titolo alle nostre colonne, mostrando solo i film successivi al 2001
#%-2s %-6s %s\n indicano la posizione delle etichette con la relativa spaziatura
gawk 'BEGIN{printf("%-2s %-6s %s\n","Anno","Voto%","Titolo")} $1>2001{print}' deniro
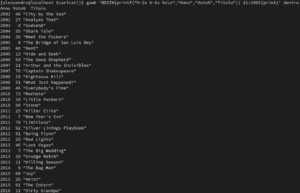 Il report con gli header.
Il report con gli header.Per rendere completo il report, aggiungiamo anche un’ultima riga di coda, che ci mostra il numero di film girati dall’attore dal 2001 in poi e la media dei voti. Ciò è possibile grazie ad un altro criterio utilizzabile in Gawk, END. Questo, simmetricamente a BEGIN, esegue la direttiva post processo dei record. Per quanti di voi non sono avvezzi alle logiche base della programmazione, questa istruzione potrebbe risultare un pochino più complessa. Vado semplicemente a creare due variabili all’inizio dell’istruzione, che si andranno via via incrementando, fino ad assumere i valori desiderati:
gawk 'BEGIN{printf("%-2s %-6s %s\n","Anno","Voto%","Titolo")} BEGIN{x=0} BEGIN{y=0} $1>2000{x+=$2} $1>2000{y+=1} $1>2000{print} END{printf("Media voti:%s\n",x/y)}' deniro
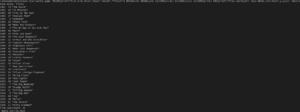 Il report completo.
Il report completo.Per approfondire ulteriori dettagli di questo potente linguaggio, vi consiglio di visionare l’apposita pagina del manuale accessibile tramite l’istruzione man gawk. Lo consiglio davvero a tutti, anche ai non tecnici. Manipolare questo tipo di file, infatti, potrebbe risultare utilissimo in tantissime occasioni.
 Seguiteci sul nostro canale Telegram, sulla nostra pagina Facebook e su Google News. Nel campo qui sotto è possibile commentare e creare spunti di discussione inerenti le tematiche trattate sul blog.
Seguiteci sul nostro canale Telegram, sulla nostra pagina Facebook e su Google News. Nel campo qui sotto è possibile commentare e creare spunti di discussione inerenti le tematiche trattate sul blog.
