
In questa semplice guida vedremo come possiamo testare Ubuntu Snappy su pc o come macchina virtuale in VirtualBox.

Tra le tante novità sviluppate / supportate da Canonical troviamo anche Ubuntu Snappy, una versione della famosa distribuzione Linux dedicata alle piattaforme IoT (Internet of Thinghs). Ubuntu Snappy fornisce un sistema operativo base creato per essere stabile e soprattutto sicuro, tutto questo è possibile grazie al nuovo gestore dei pacchetti (niente quindi apt o dpkg), ogni applicazione consiste in un tarball con tutti i file necessari per eseguire un’applicazione, senza struttura imposta di directory, dipendenze, e un singolo file di metadati che contiene il nome del pacchetto, la versione e percorsi dei file binari ecc.
Con Ubuntu 15.04 Vivid è approdata anche la versione stabile di Ubuntu Snappy, release disponibile che viene rilasciata con file immagini img solo per architetture 64 Bit o ARM. Ubuntu Snappy è un sistema base che richiede pochissime risorse, basta scaricare il file immagine ed estrarlo in una pendrive (da almeno 4 GB) utilizzando ad esempio dd da riga di comando o dd utility. 

Possiamo testare Ubuntu Snappy in VirtualBox, per farlo prendiamo la nostra distro Linux ed installiamo il tool qemu-utils digitando:
sudo apt-get install qemu-utils
a questo punto possiamo convertire l’immagine img di Ubuntu Snappy in una macchina virtuale vdi digitando:
qemu-img convert -O vdi ubuntu-*.img ubuntu-snappy.vdi
una volta effettuata la conversione basterà creare una nuova macchina virtuale e caricare il file vdi nella sezione archiviazione.
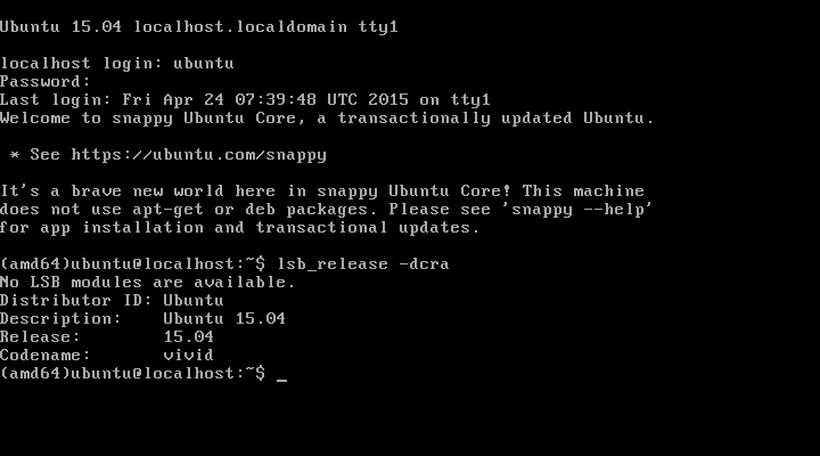
Per accedere a Ubuntu Snappy dovremo inserire le credenziali:
username: ubuntu
password: ubuntu
