

Per chi non li conoscesse i sistemi di optical character recognition (riconoscimento ottico dei caratteri detti anche OCR) sono programmi dedicati alla conversione di un’immagine contenente testo, solitamente acquisite tramite scanner, in testo digitale modificabile con un normale editor.
Kbookocr è una semplice applicazione per il riconoscimento del testo da un documento PDF.
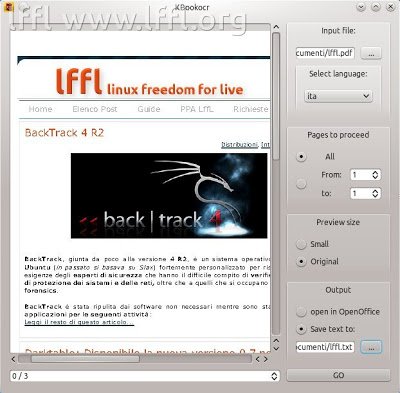
Molto semplice da utilizzare, una volta avviata l’applicazione basta cliccare su Input file, selezionare il documento da elaborare e su Select language e scegliere la lingua del documento. Ora in Pages to proceed possiamo scegliere se scansionare tutte le pagine del documento o solo alcune. Non si resta che andare su Output e scegliere dove salvare il file oppure utilizzare il testo estratto su OpenOffice.
Per installare KBookocr su Kubuntu – Debian – Fedora – OpenSUSE basta scaricare il pacchetto in QUESTA pagina
