
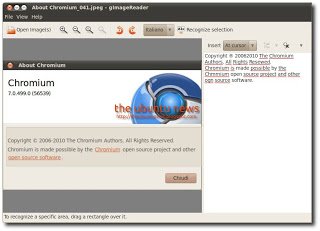
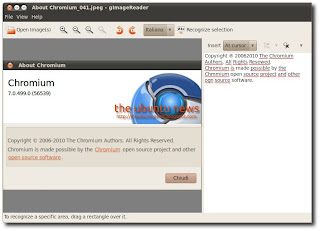
gImageReader è una semplice applicazione che utilizza tesseract-ocr per il riconoscimento del testo che sia un’immagine o un documento PDF.
Molto semplice da utilizzare, una volta avviata l’applicazione basta cliccare su OpenImage, selezionare l’immagine o documento da elaborare, a questo punto se vogliamo la scansione completa clicchiamo su Recognize Selection, se vogliamo elaborare sono una parte basta tener premuto il tasto sinistro del mouse e selezionare la parte d’immagine o di documento da elaborare e cliccare su Recognize Selection
Prima di installare l’applicazione consiglio di installare il riconoscimento Ocr in italiano per farlo basta avviare il terminale e scrivere:
sudo apt-get install tesseract-ocr-ita
ora installiamo l’applicazione scaricando QUESTO pacchetto
per avviare l’applicazione basta avviare il terminale e scrivere gimagereader
consiglio di crearci un lanciatore o meglio ancora un collegamento al nostro menu per agevolare l’avvio dell’applicazione.
